This quote from Jamie Zawinski summarizes everything you need to know about regular expressions.
"Some people, when confronted with a problem, think 'I know, I'll use regular expressions.' Now they have two problems."
Do you still want to read this chapter? Regular expressions are good to know. They can help you parse strings without having to write much code. Regular expressions are their own language that specify the make-up of an acceptable string. A matcher applies a regular expression pattern to a string to check for a match and to extract substrings.
In Sleep ismatch and hasmatch functions use regular expressions to check if a string matches a pattern. The function &matches extracts substrings based on the results of a pattern applied to a string. The function &replace uses regular expressions to specify patterns of text to replace. And the function &split uses a regular expression as the delimeter for breaking a string into several pieces.
All of this functionality uses the same underlying matcher engine. Before use the regular expression engine compiles the pattern into a state machine. The matcher then starts at the beginning of the state machine and at the beginning of your string. The matcher consumes characters from the input string until it satisfies the current state. It then tries to satisfy the next state in the state machine. The matcher "backtracks" to a previous state with another potential path when it cannot satisfy the current state. A successful match will consume the entire string and end in a success state of the pattern. The string is a non-match when these conditions aren't met.
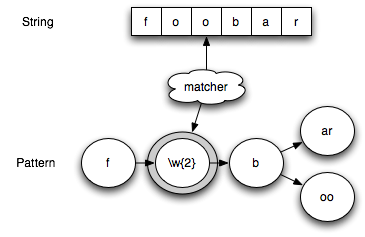
This diagram shows the string "foobar" applied to the pattern 'f\w{2}b(ar|oo)'. This pattern matches any string that begins with
"f", followed by 2 letters, followed by a "b", followed by "ar" or "oo". The arrow to from the matcher to the string represents
the current string location. The arrow from the matcher to the \w{2} state represents the current pattern element.
There are several constructs within the regular expression language you should be aware of. Pattern elements represent a set of one or more acceptable characters. Pattern elements are literal characters, character classes, and groups. Groups consist of regular expression patterns sometimes with special options or logical operators. Quantifiers repeat a pattern element a fixed or variable number of times.
Literal characters are the simplest pattern element. The pattern 'a' matches the string "a". The pattern 'ardvark' matches the
string "ardvark". Literal characters specify the only character that the matcher will accept from the current string location.
These sequences describe literal characters:
| Sequence | Meaning |
|---|---|
a | Matches the character a |
\\ | Matches the backslash character |
\0n | Matches the character at octal value n |
\0nn | Matches the character at octal value nn |
\0mnn | Matches the character at octal value mnn |
\xhh | Matches the character at hexadecimal value 0xhh |
\uhhhh | Matches the character at hexadecimal value 0xhhhh |
\t | Matches the tab character |
\n | Matches the line feed character |
\r | Matches the carriage-return character |
\f | Matches the form-feed character |
\a | Matches the alert (bell) character |
\e | Matches the escape character |
\cx | Matches the control character x |
The ismatch predicate returns true if the pattern describes the string.
$ java -jar sleep.jar >> Welcome to the Sleep scripting language > ? "this is a test" ismatch 'this is a test' true > ? "abcd" ismatch 'abce' false > ? "abcd" ismatch '\x61\x62\x63\x64' true > ? "abcd" ismatch '\u0061\x62\x63\x64' true
The matcher interprets the string it receives as the pattern. To match a single \, the regex engine requires the \\
sequence. Single and double quoted strings process '\\\\' to '\\'. Double quoted strings associate special meaning with many escaped
characters. Single quoted strings have meanings for '\\' and '\'' only. Using single quoted strings you avoid surprises.
The &split function uses a regular expression pattern as the delimeter for breaking a string into pieces.
@data = @("Raphael,Professional Escort,NY", "Frances,Sales Warrior,MI"); foreach $var (@data) { ($name, $job, $state) = split(',', $var); println("$name works as a $job in $state"); }
Raphael works as a Professional Escort in NY Frances works as a Sales Warrior in MI
Regular expression patterns are full of characters that have special meanings. Quote a character to force a literal match.
| Sequence | Meaning |
|---|---|
\ | Quotes the next character |
\Q | Begins a quote sequence |
\E | Ends a quote sequence |
A quote sequence quotes all characters within it.
> ? '\x62' ismatch '\\\\x62' true > ? "\x62" ismatch '\\\\x62' false > ? '\t\n' ismatch '\Q\t\n\E' true > ? "\t\n" ismatch '\Q\t\n\E' false
Literal characters produce matchers that can match only one string. You have to use character classes to match more than one string. A character class represents the set of all characters that the matcher will accept from the current string location.
Enclose a custom character class with square brackets. It is a common to confuse character classes with groups. Character classes match a single character. A group matches a sequence of characters.
A custom character class:
^&& to combine acceptance criteria from another custom character class| Sequence | Meaning |
|---|---|
[abc] | Matches a, b, or c |
[c-m] | Matches any character c through m |
[ab[xy]] | Matches a, b, x, or y |
[^0-9] | Matches any non-digit |
[a-m&&[bar] | Matches a or b |
[a-z&&[^w-y] | Matches a through z except for w, x, and y. |
Examples:
> ? "r" ismatch '[bar]' true > ? "bar" ismatch '[bar]' false > ? "34a" ismatch '[0-9][0-9][a-z]' true > ? "34A" ismatch '[0-9][0-9][a-z]' false
Several built-in character classes exist. These save you the trouble of defining custom character classes.
| Sequence | Meaning |
|---|---|
. | Matches anything |
\d | Matches any digit 0-9 |
\D | Matches any non-digit |
\s | Matches any whitespace character |
\S | Matches any non-whitespace character |
\w | Matches any word character (a-z, A-Z, _, and 0-9) |
\W | Matches any non-word character |
For historical reasons, POSIX character classes exist as well.
| Sequence | Meaning |
|---|---|
\p{Lower} | Matches a lower-case letter |
\p{Upper} | Matches an upper-case letter |
\p{ASCII} | Matches all ASCII characters |
\p{Alpha} | Matches a letter |
\p{Digit} | Matches a digit 0-9 |
\p{Alnum} | Matches a number or letter |
\p{Punct} | Matches one of !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~ |
\p{Graph} | Matches a number, letter, or punctuation character |
\p{Print} | Matches a printable character. Same as \p{Graph} |
\p{Blank} | Matches a space or a tab |
\p{Cntrl} | Matches a control character |
\p{XDigit} | Matches a hexadecimal digit |
\p{Space} | Matches a whitespace character |
Sleep patterns can use blocks and categories from the Unicode specification. See http://unicode.org/reports/tr18/ for more information.
| Sequence | Meaning |
|---|---|
\p{InGreek} | Matches a character in the Greek block (simple block) |
\p{Lu} | Matches an uppercase letter (simple category) |
\p{Sc} | Matches a currency symbol |
You may negate posix class definitions with an uppercase \P:
| Sequence | Meaning |
|---|---|
\P{ASCII} | Matches anything except ASCII characters |
[\p{Space}&&\P{Blank}] | Matches any whitespace except for a space or a tab |
Examples:
> ? "X" ismatch '.' true > ? "\x00" ismatch '.' true > ? "34" ismatch '\d\d' true > ? "E4" ismatch '\d\d' false > ? '$33' ismatch '\p{Sc}\d\d' true
A group encloses one or more pattern elements with parentheses. A group represents a sequence of pattern elements that the matcher must accept from the current string location.
The pipe character specifies alternate acceptable patterns. 'foo|bar' matches the strings "foo" or "bar". The alternation
operator can lead to slow matcher performance. Avoid it if possible.
| Sequence | Meaning |
|---|---|
XY | Matches X followed by Y |
X|Y | Matches the sequence X or Y |
Examples:
> ? "foobar" ismatch 'f\w\wb(ar|oo)' true > ? "fayboo" ismatch 'f\w\wb(ar|oo)' true > ? "foobor" ismatch 'f\w\wb(ar|oo)' false
All groups are capture groups by default. Capture groups are numbered from 1 to n by counting the opening parentheses from left to right. Group 0 represents the entire match.
The matcher saves matched substrings during processing. The matcher tracks substrings by capture group. You can use a backreference to
recall a capture group. A backreference is the backslash character followed by a capture group number. As an example, '(foo|bar)\1' matches
"foofoo" or "barbar" but not "foobar" or "barfoo". The \1 in the pattern recalls of the text from the first
capture group.
A group prefixed with a question mark and a colon is a non-capturing group. These groups do not save substrings and do not affect the capture group count.
| Sequence | Meaning |
|---|---|
(?:X) | Matches X as a non-capturing group |
(X) | Matches X as a capturing group |
\n | Matches whatever the nth capturing group matched |
The &matched function returns the matches from the last ismatch or hasmatch comparison.
if ("(654) 555-1212" ismatch '\((\d\d\d)\) (\d\d\d-\d\d\d\d)') { ($areaCode, $phoneNumber) = matched(); println("dial 1 and $areaCode before $phoneNumber"); }
dial 1 and 654 before 555-1212
As a shortcut, the &matches function carries out the comparison and extraction operations in one call.
# trim whitespace from start of a string $trimmed = matches("\t this is a test", '\s*(.*)')[0]; println($trimmed);
this is a test
The &replace function recalls capture group elements as well. The literal values '$1' .. '$n' in the replacement value are substituted for the recalled
text. This example changes bold html tags to underline:
$bold = 'This string has <b>bolded</b> text and <b>lots of it</b> :)'; $underline = replace($bold, '<b>(.*?)</b>', "<u>\$1</u>"); println($underline);
This string has <u>bolded</u> text and <u>lots of it</u> :)
The ismatch predicate anchors itself to the beginning and end of a string by default. The cousin to ismatch is the hasmatch predicate. hasmatch looks for a substring within the string that satisfies the specified pattern. Moreover this predicate remembers the last substring it matched. Subsequent calls to hasmatch will return the next matching substring until no more matching substrings exist. At this point hasmatch returns false and clears its state information.
sub printDocumentTree { local('$tag $content'); while ($1 hasmatch '<(.*?)>(.*?)</\1>') { ($tag, $content) = matched(); println((" " x $2) . "+- $tag $+ : $content"); printDocumentTree($content, $2 + 1); } } $html = "<html><title>Hello World!</title><p>It's a <b>nice</b> day</p></html>"; printDocumentTree($html, 0);
+- html: <title>Hello World!</title><p>It's a <b>nice</b> day</p> +- title: Hello World! +- p: It's a <b>nice</b> day +- b: nice
So far we have seen patterns that accept a fixed length string. To match two digits requires '\d\d'. Literal characters and character classes let you specify what
to match. Can you construct a pattern to match 2-3 digits? With what I've shown you so far, you can't.
The specification of how many is left to quantifiers. Quantifiers attach a repetition quantity to pattern elements. This quantity specifies how many times an element can repeat.
The following table shows the available quantifiers.
| Sequence | Meaning |
|---|---|
X? | Matches X once or not at all |
X* | Matches X zero or more times |
X+ | Matches X one or more times |
X{n} | Matches X exactly n times |
X{n,} | Matches X at least n times |
X{n,m} | Matches X at least n but no more than m times |
Examples:
> ? "ooooooooh yeah!" ismatch 'o+h yeah!' true > ? "0o0o0o0h yeah!" ismatch '[o0]+h yeah!' true > ? "89 bottles of beer on the wall" ismatch '\d{1,2} bottles of beer on the wall' true > ? "100 bottles of beer on the wall" ismatch '\d{1,2} bottles of beer on the wall' false > ? "" ismatch '.*' true
Quantifiers consume characters in a greedy manner by default. A greedy quantifier will consume as many characters as possible before moving on to the next pattern element. If a match fails and a greedy quantifier is present, the matcher will backtrack and have the greedy quantifier give back a character. The matcher will then try to complete the match. If this fails it will go back to the greedy quantifier and ask for a character again. The matcher repeats this process until it accepts the string or there are no characters left to give back.
> ? '123456' ismatch '(\d+)(\d+)' true > x matches('123456', '(\d+)(\d+)') @('12345', '6')
A possessive quantifier will consume as much of the string as possible. Possessive quantifiers differ from greedy quantifiers in how they respond to a match failure. A possessive quantifier will not give back characters like a greedy quantifier does. This will cause some matches that succeed with a greedy strategy to fail. The tradeoff is possessive quantifiers fail much faster than greedy quantifiers. Append a plus to make a quantifier use a possessive strategy.
> ? '123456' ismatch '(\d++)(\d++)' false
A relucant quantifier will consume as few characters as possible before moving to the next pattern element. Append a question mark to make a quantifier use a reluctant strategy.
> x matches('123456', '(\d+?)(\d+)') @('1', '23456')
A look around construct is a means to ask prequalifying questions about the rest of the input string before continuing with the match. Look arounds do not consume characters.
These constructs are summarized here:
| Sequence | Meaning |
|---|---|
(?=X) | Checks for X to occur later |
(?!X) | Checks that X does not occur later |
(?<=X) | Checks that X has occured |
(? | Checks that X has not occured |
(?>X) | Checks for X |
An example:
if ('http://www.google.com/' ismatch '(?=http://)(.*)') { ($url) = matched(); println($url); }
http://www.google.com/
Notice that the http:// portion of the pattern is not consumed. It is merely a precondition for the matcher to continue matching the rest of the string.
hasmatch, &replace, and other regex functionality do not anchor themselves to specific portions of a string. Boundary matchers exist to allow a pattern to anchor itself. The boundary matchers for pattern anchoring are listed below:
| Sequence | Meaning |
|---|---|
^ | Matches the beginning of a line |
$ | Matches the end of a line |
\b | Matches a word boundary |
\B | Matches a non-word boundary |
\A | Matches the beginning of the input |
\G | Matches the end of the previous match |
\Z | Matches the end of the input but for the final terminator, if any |
\z | Matches the end of the input |
This example uses &replace to replace instances of foo or bar only if they occur at the beginning of a string:
$string = replace("foo is the word, not bar!", '\Afoo|\Abar', "pHEAR"); println($string);
pHEAR is the word, not bar!
The matcher engine is tweakable with a few parameters. These options are enabled and disabled as specified in the table:
| Sequence | Meaning |
|---|---|
(?idm-sux) | Sets matcher options [on: idm] [off: sux] |
(?ids-mu:X) | Sets matcher options in a non-capturing group: [on: ids] [off: mu] |
The option:
i makes pattern matching case insensitive for ASCII charactersu sets case insensitive matching for Unicode charactersd option enables UNIX lines mode. This mode forces the matcher to recognize only "\n" as a new linem option enables multiline mode which makes the ^ and $ boundary matchers match at the beginning/end of each lines flag allows the . built-in class to match any character including new linesx option forces the matcher to ignore white space and allow pattern comments. Pattern comments begin with a pound sign. and end with a
newline.$pattern = '(?x) # ignore whitespace and enable comments (?=http://) # look ahead for http:// first (.*) # put the string into a capture group'; if ("http://sleep.dashnine.org/" ismatch $pattern) { ($url) = matched(); println($url); }
http://sleep.dashnine.org/